Utilisation de fossil
Introduction
fossil-scm est un gestionnaire de versions entièrement écrit en C. Le code de sqlite est maintenu via fossil, et son site web est également propulsé par fossil.
L'approche est différente de git-scm; une fois compilé, fossil est un exécutable qui se suffit et vient avec une interface web, un wiki, un forum, un chat, et une page d'administration permettant de gérer les droits d'accès. Il est pensé pour être utilisé par une petite équipes de personnes se connaissant et travaillant ensemble, contrairement à git fonctionnant plutôt à base de pull/merge request.
L'historique du code et autres informations sont stockés dans une
base de données sqlite (un seul fichier donc). Lorsque l'on travaille à
plusieurs sur un projet fossil, celui-ci suppose que chaque utilisateur
dispose d'une connexion internet et réalise un auto-sync (cela évite des futures merge
conflicts).
Installation
Ici nous allons voir l'utilisation de fossil en ligne de commande.
Sous debian-like, un simple apt install fossil installe tout ce qu'il faut.
La page de
téléchargements propose des fichiers binaires pour différents
OS.
Il existe des plugins pour différents éditeur de code, comme visual studio ou jetbrains.
Mise en place
Pour travailler en local, il est conseillé d'avoir un dossier qui contiendra tous nos projets fossil. Un backup de ce dernier permettra de ne perdre aucun code ni historique. Nous allons le placer dans notre répertoire personnel.
mkdir -p ~/fossil
Ensuite, si l'on souhaite travailler sur un projet, comme projet1, nous allons créer un projet fossil du
même nom, avec l'extension .fossil.
fossil init ~/fossil/projet1.fossil
Vous êtes libre de créer d'autres projets, et de créer des sous-dossiers par année, par exemple:
mkdir -p ~/fossil/2024-2025/{c,java}
fossil init ~/fossil/2024-2025/c/projet1.fossil
fossil init ~/fossil/2024-2025/c/projet2.fossil
fossil init ~/fossil/2024-2025/java/projet2.fossil
fossil init ~/fossil/2024-2025/java/projet2.fossil
L'avantage de cette approche, c'est que l'on peut avoir accès à l'interface web de ces projets via la commande:
fossil ui ~/fossil
Ceci ouvrira votre navigateur web avec une page listant vos
différents projets. Ces projets sont indépendants: lors
d'un fossil init, un utilisateur et un mot
de passe aléatoire sont créés. Tant que vous travaillez localement, cela
n'a pas d'importance, car la commande fossil ui vous donne accès directement à
l'interface admin du projet.
Reprenons l'exemple initial, vous souhaitez travailler sur un nouveau
projet nommé projet1. Vous disposez déjà
de ~/fossil/projet1.fossil. Vous allez
écrire votre code où vous le souhaitez, par exemple dans ~/cours/hers/2024-2025/c/projet1.
Vous faites donc:
mkdir -p ~/cours/hers/2024-2025/c/projet1
cd ~/cours/hers/2024-2025/c/projet1
fossil open ~/fossil/projet1.fossil
Un nouveau fichier s'est créé dans votre dossier vierge:
~/cours/hers/2024-2025/c/projet1/.fslckout
Vous ne devez pas toucher à ce fichier, vous pouvez même l'ignorer
complètement, il contient notamment l'information d'où se trouve le
projet ~/fossil/projet1.fossil.
Remarque: si vous aviez déjà commencé à créer du
code, et que vous effectuez la commande fossil open, celle-ci ne fonctionnera pas, à
moins de rajouter l'option -f:
fossil open -f ~/fossil/projet1.fossil
Commencer à coder
Les commandes essentiels sont les suivantes:
fossil add # Rajouter des fichiers à surveiller par fossil
fossil commit # Enregistrer les modifications effectuées
fossil extra # Voir les fichiers qui ne sont pas surveillés par fossil
fossil changes # Voir un résumé des changements (ajout / supression
# ou modification de fichiers)
fossil diff # Lance la commande `diff` sur les fichiers du repo par
# rapport au checkin précédent
fossil ui # Lancer le serveur web
fossil update # Synchroniser le projet local avec un projet distant
fossil revert # Revenir à une version antérieure d'un ou plusieurs fichiers
Si vous créez un fichier nommé test.c,
par défaut fossil ne va pas surveiller les modifications que
vous lui apportez. Utilisez la commande
fossil extra
pour voir tous les fichiers de votre projet qui ne sont pas surveillés par fossil. Si vous souhaitez qu'ils le soient, faites la commande suivante:
fossil add FICHIER1 FICHIER2 ...
Ensuite, pour enregistrer vos modifications:
Soit pour tous les fichiers surveillés par fossil:
fossil commitSoit pour un ou plusieurs fichiers choisis:
fossil commit FICHIER1 FICHIER2 ...
And that's all folks! Rien qu'avec ces commandes, vous maintenez un historique de vos codes.
En ligne (seul ou pour collaborer)
Pour collaborer, le mieux est de déployer fossil telle que le prévoit la doc. Un serveur est disponible sur https://fossil.infohers.org/, il vous suffit de faire une demande d'ajout d'un projet.
Une personne crée un projet fossil, via
fossil init ~/fossil/myproject.fossilStocker le nom d'utilisateur et le mot de passe.
Rendre le repo privé. Lancer le serveur web
fossil ui ~/fossil/myproject.fossilPuis allez dans
Admin > Security Audit, puis cliquez sur Take it private.
Dans ce cas, seul l'admin pourra accéder au repo.
La page Security Audit donne un résumé des droits.
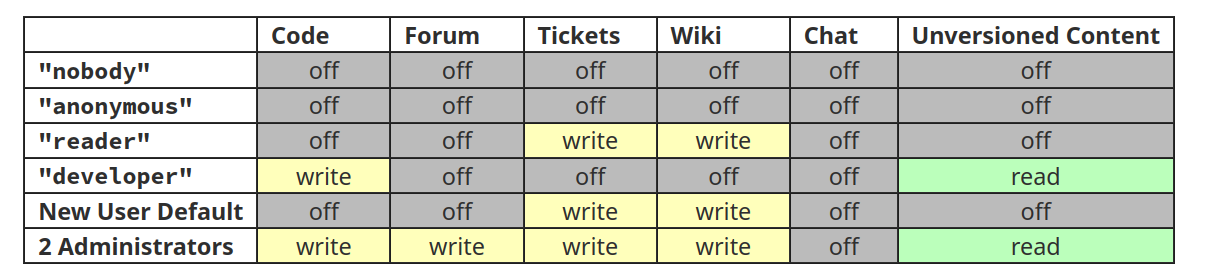
Vous pouvez vous-même modifier ces droits dans
Admin > Users.Transmettez votre repo par e-mail afin que je le place sur https://fossil.infohers.org/.
Pour collaborer, il faut rajouter des utilisateurs. Pour ce faire, allez dans
Admin > Users, et cliquez surAdd.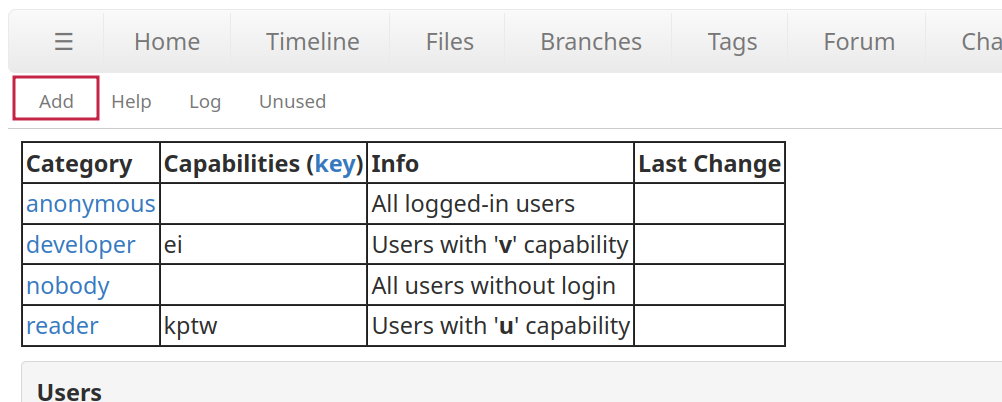
Vous devez donner un nom d'utilisateur, attribuer des droits (par exemple admin), puis créer un mot de passe ou copier-coller celui par défaut.
Créez un dossier où coder et spécifier l'url du repo fossil.
mkdir -p ~/cours/hers/c/myproject cd ~/cours/hers/c/myproject fossil open ~/fossil/myproject.fossil fossil remote https://fossil.infohers.org/myproject.fossil # voir lien donnéTransmettez le lien vers le repo fossil. Le collaborateur doit cloner le repo pour travailler dessus.
mkdir -p ~/fossil fossil clone https://USER:PASSWORD@fossil.infohers.org/myproject.fossil ~/fossil/myproject.fossil mkdir -p ~/cours/hers/c/myproject cd ~/cours/hers/c/myproject fossil open ~/fossil/myproject.fossil
Chaque commit réalisera un auto-sync avec le serveur.